Iaroslav V. Ponomarenko
I am a third-year master’s student in Computer Science at the Center on Frontiers of Computing Studies (CFCS), Peking University, supervised by Professor Hao Dong. I am also a visiting student researcher at the Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI), mentored by Professor Yoshihiko Nakamura.
Before joining Peking University, I earned an Engineer (Specialist) degree in Information Systems and Technologies from the Voronezh Institute of High Technologies and a Technician Diploma in Automated Information Processing and Control Systems from the Borisoglebsk College of Informatics and Computer Engineering.

Research focus
I’m fascinated by how we can build machines that don’t just act, but understand. Systems that see the world, reason about it, and adapt to it in ways that mirror how humans make sense of their surroundings. My research explores the space where perception becomes thought and thought becomes action, grounding intelligent behavior in models of affordance, causality, and intent. I design agents that bridge instinct and insight, creating robots that can anticipate, explain, and question to understand the world. These efforts move toward a larger goal of developing systems that perceive, act, and reason with an awareness of structure, intent, and purpose, learning from the very dynamics that make the world, and intelligence itself, alive.
News
-
Commenced a visiting student appointment at MBZUAI (Abu Dhabi, United Arab Emirates).
-
Concluded a one-year research internship at AGIBot (Beijing, China).
-
Presented ManipVQA7 at IROS 2024; certificate issued (Abu Dhabi, United Arab Emirates).
-
Presented ManipVQA7 at Microsoft Research Asia Summer Tech Fest (Beijing, China).
-
Began a research internship at AGIBot (Beijing, China).
-
Commenced Master’s studies in Computer Science at Peking University (Beijing, China).
-
Concluded a three-month visiting student appointment at Peking University (Beijing, China).
-
Commenced a visiting student appointment at Peking University (Beijing, China).
Publications
(*) Equal contribution. (†) Corresponding author. Highlighted entries denote papers selected for special recognition.
-
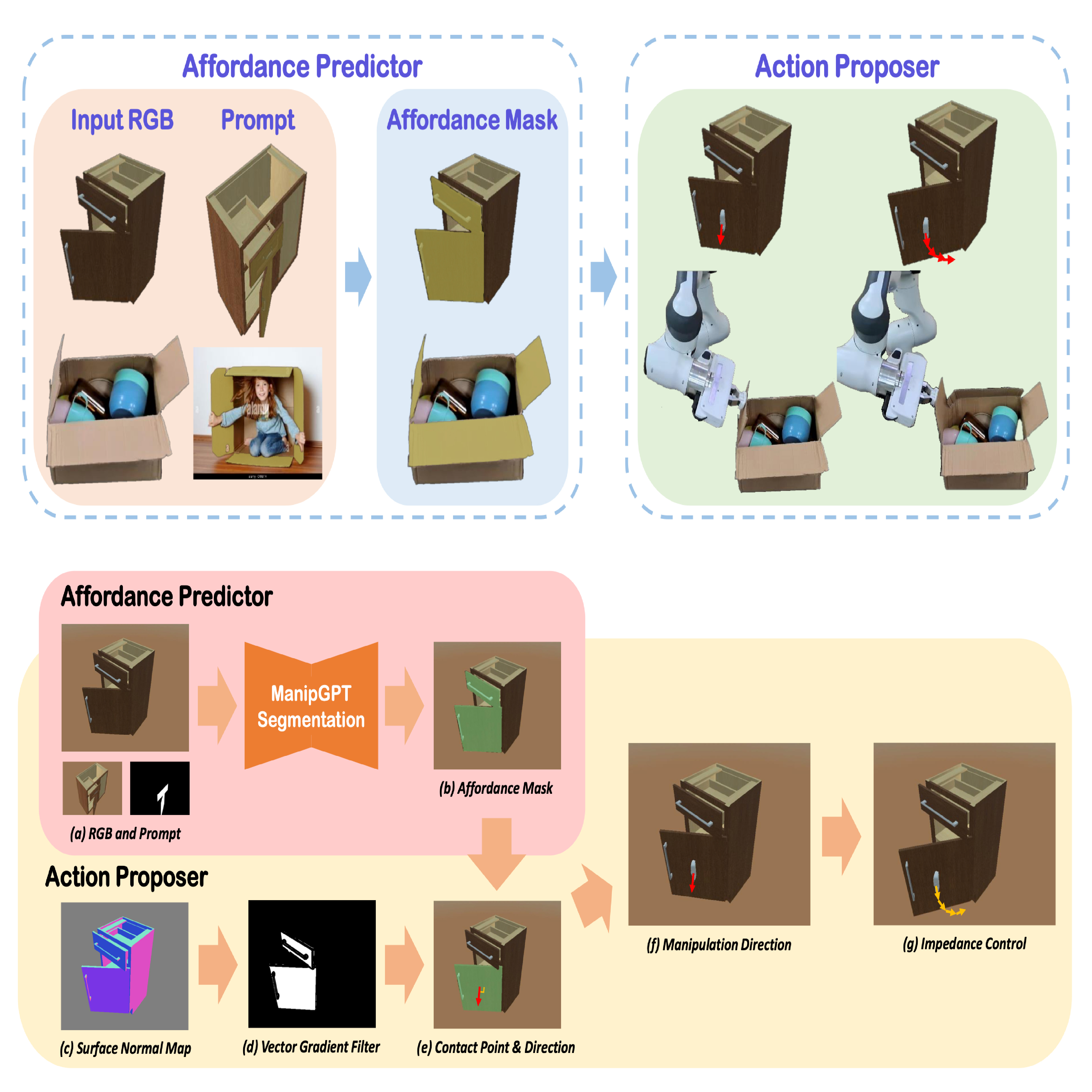
Video abstract for ManipGPT Kim, T., Bae, H., Li, Z., Li, X., Ponomarenko, I., Wu, R. & Dong, H.†. ManipGPT – is affordance segmentation by large vision models enough for articulated object manipulation? Proc. IROS (2025).
-
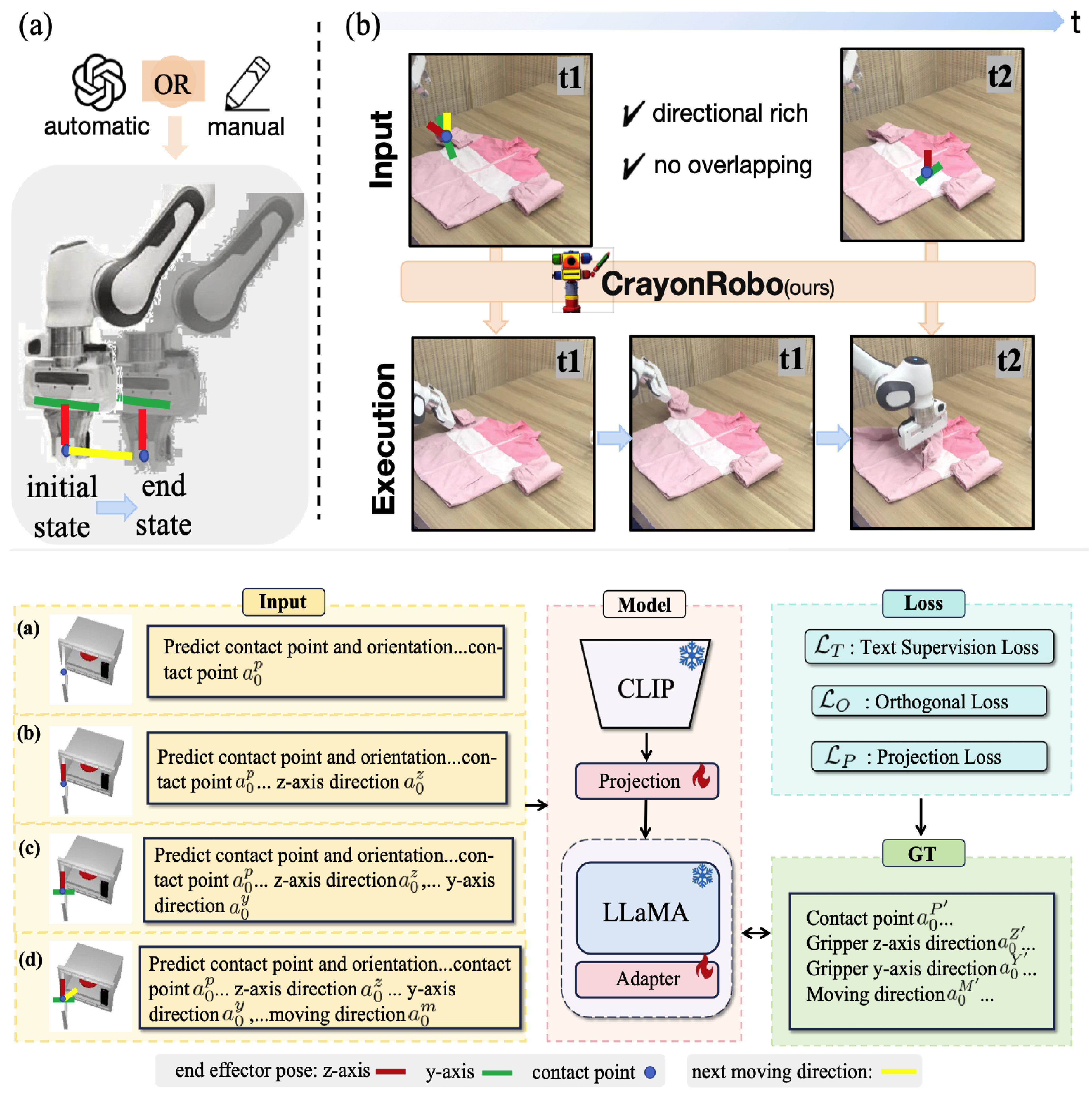
Video abstract for CrayonRobo Li, X., Xu, L., Zhang, M., Liu, J., Shen, Y., Ponomarenko, I., Xu, J., Heng, L., Huang, S., Zhang, S. & Dong, H.†. CrayonRobo – object-centric prompt-driven vision-language-action model for robotic manipulation. Proc. CVPR (2025).
-

Video abstract for SpatialBot Cai, W.*, Ponomarenko, I.*, Yuan, J., Li, X., Yang, W., Dong, H. & Zhao, B.†. SpatialBot – precise spatial understanding with vision language models. Proc. ICRA (2025).
-

Video abstract for ManipVQA Huang, S.*, Ponomarenko, I.*, Jiang, Z., Li, X., Hu, X., Gao, P., Li, H. & Dong, H.†. ManipVQA – injecting robotic affordance and physically grounded information into multi-modal large language models. Proc. IROS (2024). [Oral Pitch]
- IEEE Xplore ·
- Oral Pitch ·
- Slides ·
- Poster ·
-
GitHub
-
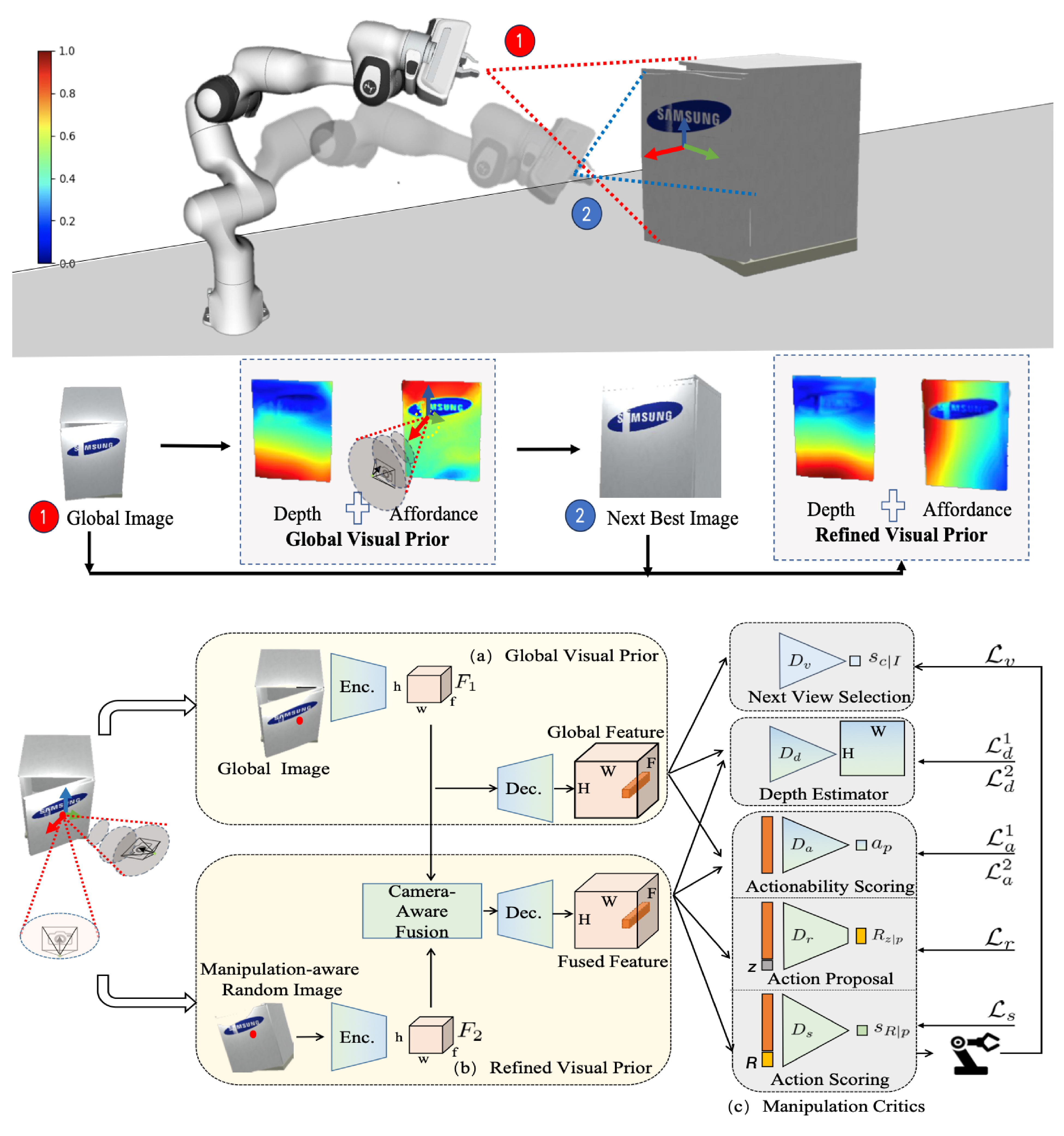
Video abstract for ImageManip Li, X., Wang, Y., Shen, Y., Ponomarenko, I., Lu, H., Wang, Q., An, B., Liu, J. & Dong, H.†. ImageManip – image-based robotic manipulation with affordance-guided next view selection. Preprint (2023).
-
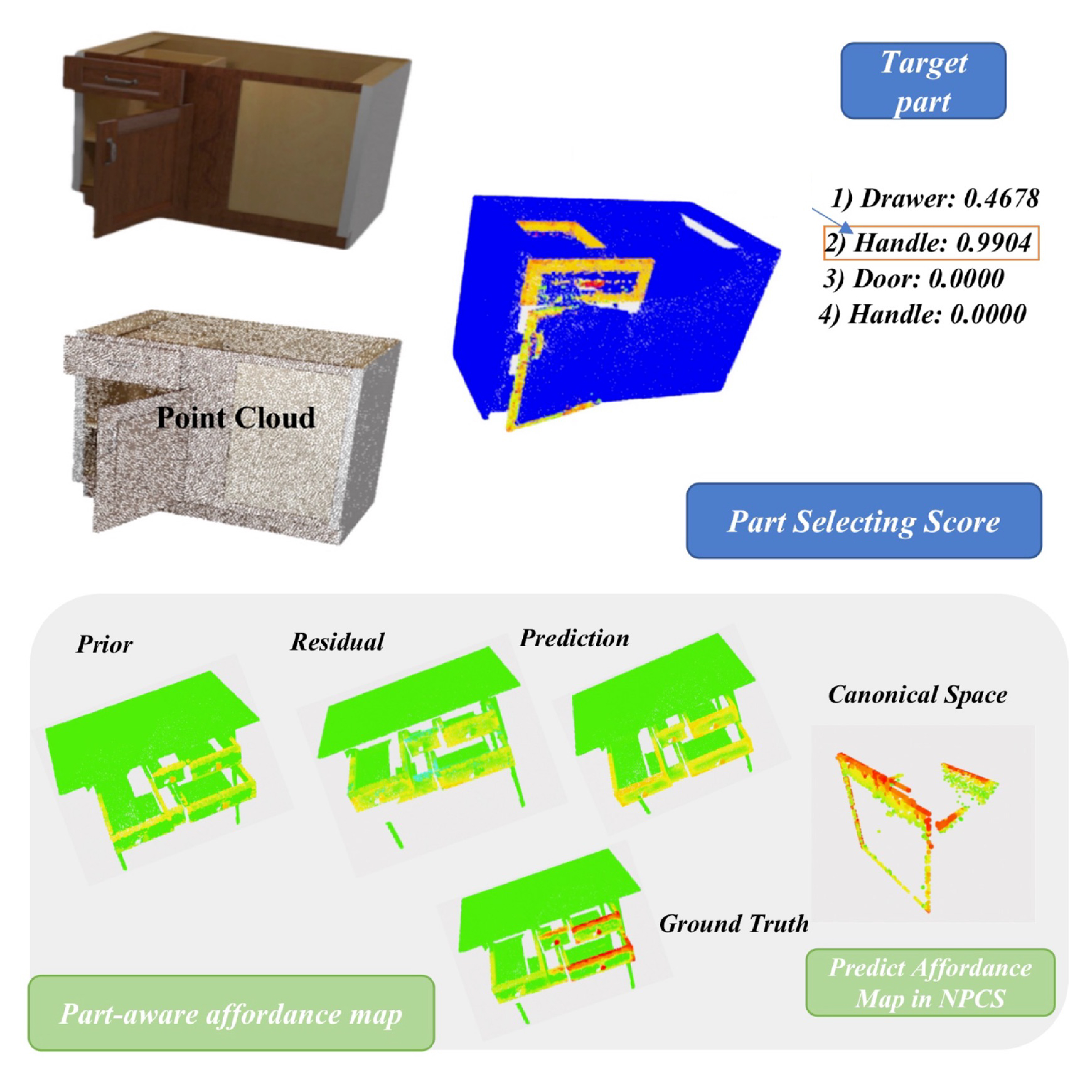
Video abstract for LPAVAA3DOM Ju, Y., Geng, H., Yang, M., Geng, Y., Ponomarenko, I., Kim, T., Wang, H. & Dong, H.†. Learning part-aware visual actionable affordance for 3D articulated object manipulation. Proc. CVPR 3DVR (2023). [Spotlight]
-
Sukhanov, A. A. & Ponomarenko, I. V.. Application of block periodization in the design of health-prolonging training cycles. Proc. of Interregional Final Scientific Student Conferences: “Student Science” and “Young Scientists” 354, 275–279 (2017).
-
Sukhanov, A. A., Ponomarenko, I. V. & Rubin, V. S.†. The potential of instrumental methods for medical soft tissue diagnostics in physical education and health-improving training. Proc. of the All-Russian Scientific Online Conference: Fitness–Aerobics 2016 226, 97–98 (2016).
-
Sukhanov, A. A., Ponomarenko, I. V. & Rubin, V. S.†. The study of methodological approaches to intermuscular coordination and strength development in women of early adulthood engaged in health-improving training. Proc. of the All-Russian Scientific Online Conference: Fitness–Aerobics 2016 226, 98–100 (2016).
-
Sukhanov, A. A. & Ponomarenko, I. V.. Assessment of the muscle condition as one of the physical health indicators in the framework of physical education and health-improving training. Proc. of Students and Young Scientists of the Russian State University of Physical Education, Sport, Youth and Tourism 279, 78–80 (2016).


Service
Conference Reviewer: RSS (2025), ICRA (2025, 2026); Membership: IEEE (2024–present), CAAI (2024–2029); Teaching Assistant: Fundamentals of AI, Peking University (Spring 2024).